Positive Definite Matrices - A Primer
October 09, 2025
A real-valued matrix $\textbf{A}$ is said to be positive definite if, for every real-valued vector $\textbf{x}$,
\[\begin{equation} \textbf{a}^\top\textbf{Ax}>0,\quad\textbf{x}\neq 0 \end{equation}\]The matrix is positive semi-definite if
\[\begin{equation} \textbf{x}^\top\textbf{Ax}\geq 0. \end{equation}\]If these inequalities are reversed, then $\textbf{A}$ is called negative definite or negative semi-definite, respectively. If neither inequality holds uniformly, then the matrix is said to be indefinite. Although these definitions can be generalised to complex-valued matrices, the present discussion will be restricted to real-valued matrices.
In statistics, positive semi-definite (PSD) matrices frequently comes up because the covariance matrices are always positive semi-definite and the definition can appear very abstract. However we need to know what PSD represent geometrically. Why must covariance matrices satisfy this condition? Why do positive semi-definite matrices occur so naturally in quadratic programming? Moreover, why does the set of all positive semi-definite matrices form a cone? The purpose of this post is to develop a clearer intuition for these questions.The discussion will rely primarily on geometric interpretations of matrices and dot products.
Multivariate positive numbers
To begin, let us temporarily set aside the formal definition of positive semi-definiteness and instead develop an intuitive interpretation.
Positive definite matrices may be understood as multivariate analogues of strictly positive real numbers, while positive semi-definite matrices may be understood as multivariate analogues of non-negative real numbers. Consider a scalar $a$. If $a<0$, then the sign of $ab$ depends on the sign of $b$. By contrast, if $a>0$, then $ab$ has the same sign as $b$. We may regard $a$ and $b$ as one-dimensional vectors and interpret their product as a dot product:
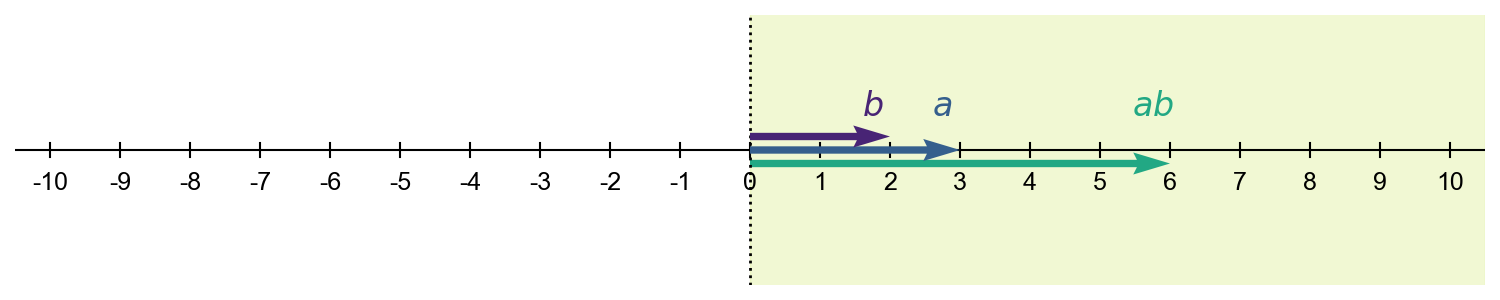
\[\begin{equation} \textbf{a}^\top\textbf{b}=\large[a\large]^\top\large[b\large]=ab. \end{equation}\]When $\textbf{a}$ is positive, the quantity $\textbf{a}^\top\textbf{b}$ lies on the same side of the origin $0$ as $\textbf{b}$. In this sense, $\textbf{a}$ does not “flip” $\textbf{b}$ across the origin. Rather, it stretches $\textbf{b}$ while preserving its direction, as illustrated in Figure $1$.
Analogously, a positive definite matrix behaves like a positive number in the sense that it does not reverse a vector through the origin. The simplest example is a diagonal matrix with positive diagonal entries, which scales each coordinate of a vector without reversing its orientation. Conversely, a diagonal matrix with negative entries may reverse the direction of a vector and is therefore not positive definite, as shown in Figure $2$.
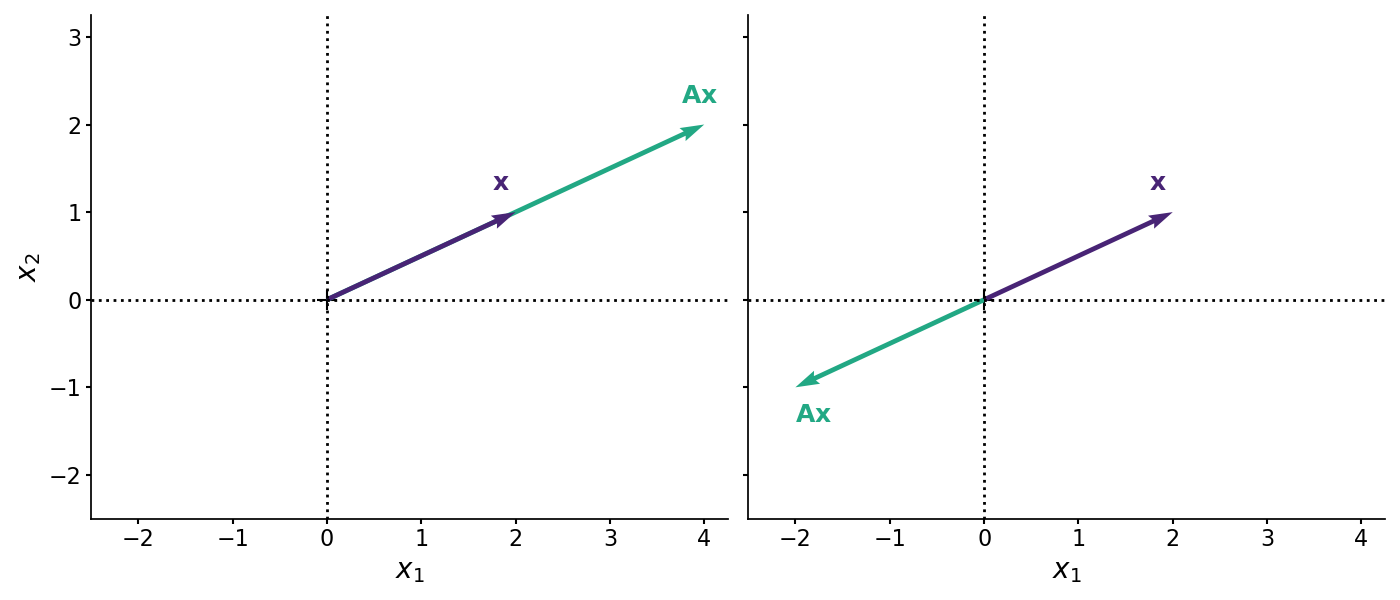
This interpretation is less immediate when the matrix $\textbf{A}$ does more than simply scale a vector by a constant. For example, does the transformation in the left panel of Figure $3$ reverse the vector $\textbf{x}$ relative to the origin? What about the transformation shown in the middle panel? To make this intuition precise, we turn to the dot product. The dot product between two $N$-dimensional vectors is defined as
\[\begin{equation} \mathbf{x}^\top \mathbf{y}=\sum_{i=1}^{N}x_ny_n, \end{equation}\]and may be interpreted as a form of vector-matrix multiplication. Equivalently, it can be understood as projecting the vector $\mathbf{y}$ onto a real number line determined by the rows or columns of a suitable $1\times N$ matrix. A second, geometrically useful expression for the dot product is
\[\begin{equation} \mathbf{x}^\top \mathbf{y}=\Vert\mathbf{x}\Vert \mathbf{y}\Vert\cos\theta. \end{equation}\]This formulation implies that two nonzero vectors $\mathbf{x}$ and $\mathbf{y}$ are orthogonal precisely when their dot product is zero:
\[\begin{equation} \mathbf{x}^\top \mathbf{y}=0. \end{equation}\]Indeed, if neither vector is the zero vector and their dot product is zero, then the cosine of the angle between them must be zero. Hence, the angle between the two vectors is $90\degree$; see the right panel of Figure $3$.

If the dot product between two nonzero vectors is positive,
\[\begin{equation} \mathbf{x}^\top \mathbf{y}>0, \end{equation}\]then the vectors point in broadly similar directions: the angle between them is acute, meaning less than $90\degree$; see Figure $3$, left. Conversely, if the dot product is negative,
\[\begin{equation} \mathbf{x}^\top \mathbf{y}<0, \end{equation}\]then the vectors point in broadly opposite directions: the angle between them is obtuse, meaning greater than $90\degree$; see Figure $3$, middle.
Thus, one geometric interpretation of positive definiteness is that the matrix $\mathbf{A}$ never maps a nonzero vector $\mathbf{x}$ to a vector $\mathbf{Ax}$ lying in the opposite half-space. Equivalently, the angle between $\mathbf{x}$ and $\mathbf{Ax}$ remains between $-90\degree$ and $90\degree$. In this sense, $\mathbf{x}$ and $\mathbf{Ax}$ lie in the same half of an $N$-dimensional hypersphere, as illustrated in Figure $4$.
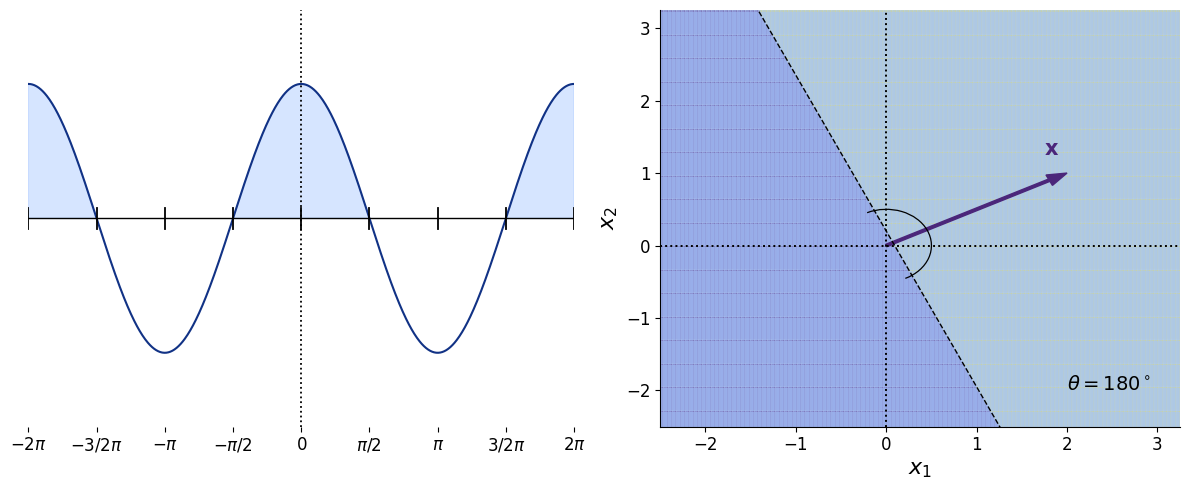
Figure $4$ expresses the geometric content of Equation $1$. This becomes clearer if the dot product notation is written explicitly:
\[\begin{equation} \mathbf{x}\cdot \mathbf{Ax}>0. \end{equation}\]Here, $\mathbf{a}\cdot \mathbf{b}$ denotes the standard dot product. This condition is analogous to defining a positive real number $a$ by requiring that
\[\begin{equation} b(ab)>0, \end{equation}\]for every scalar $b\neq 0$. In summary, an $N\times N$ matrix is positive definite if it maps every nonzero vector into the same half of the corresponding $N$-dimensional hypersphere. Geometrically, this is the matrix-valued analogue of a positive real number.
Examples
Now that we have both a formal definition and a geometric interpretation of positive semi-definite matrices, let us consider several examples. First, consider the matrix
\[\begin{equation} \mathbf{A}= \begin{bmatrix} 1 & 0 \\ 0 & 3 \end{bmatrix} \end{equation}\]This matrix is positive semi-definite since
\[\begin{equation} \begin{bmatrix} x_1 & x_2 \\ \end{bmatrix} \begin{bmatrix} 1 & 0 \\ 0 & 3 \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \end{bmatrix} = x_1^2+3x_2^2\geq 0. \end{equation}\]This calculation suggests that any diagonal matrix with non-negative diagonal entries is positive semi-definite. Since the diagonal entries of a diagonal matrix are also its eigenvalues, it is natural to conjecture that positive semi-definite matrices are characterised by non-negative eigenvalues. As we shall see in the next section, this intuition is correct.
Next, consider the singular matrix
\[\begin{equation} \mathbf{A}= \begin{bmatrix} 1 & 1 \\ 1 & 1 \\ \end{bmatrix} \end{equation}\]This matrix is also positive semi-definite since
\[\begin{equation} \begin{bmatrix} x_1 & x_2 \\ \end{bmatrix} \begin{bmatrix} 1 & 1 \\ 1 & 1 \\ \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \end{bmatrix} = \left(x_1^2+x_2\right)^2\geq 0. \end{equation}\]Thus, a matrix need not be invertible in order to be positive semi-definite. However, as discussed below, a positive definite matrix must have strictly positive eigenvalues.
Now consider an example of an indefinite matrix:
\[\begin{equation} \mathbf{A}= \begin{bmatrix} 1 & -2 \\ 2 & -1 \\ \end{bmatrix} \end{equation}\]This matrix is indefinite since
\[\begin{equation} \begin{bmatrix} x_1 & x_2 \\ \end{bmatrix} \begin{bmatrix} 1 & -2 \\ 2 & -1 \\ \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \end{bmatrix} = x_1^2-x_2^2\ngeq 0 \end{equation}\]However, a matrix need not contain negative entries in order to be indefinite. Consider the following matrix, whose entries are all positive:
\[\begin{equation} \mathbf{A}= \begin{bmatrix} 3 & 5 \\ 5 & 4 \\ \end{bmatrix} \end{equation}\]Then
\[\begin{equation} \begin{bmatrix} x_1 & x_2 \\ \end{bmatrix} \begin{bmatrix} 3 & 5 \\ 5 & 4 \\ \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \\ \end{bmatrix} = 3x_1^2+10x_1x_2+4x_2^2. \end{equation}\]It is not immediately evident whether this quadratic expression is always non-negative, since the cross term $10x_1x_2$ can be negative when $x_1$ and $x_2$ have opposite signs. In fact, this matrix is not positive semi-definite: for suitable choices of $\mathbf{x}$, the quadratic form $\mathbf{x}^\top \mathbf{Ax}$ is negative.
These examples indicate that a more systematic understanding is needed. In particular, we require general mathematical criteria for identifying when a matrix is positive definite or positive semi-definite.